How To Not Get Stuck
Early in my software engineering career, I would regularly find myself to be stuck. Whether it was trying to find the cause of a bug, or not knowing the right way to accomplish what was outlined in a task, I would reach a point where I needed to ask for help. Asking for help can be difficult. When you’re in junior or even mid-level positions, it’s common to feel like you’re asking for help with _everything—_that you can’t finish a single task without feedback or guidance from a senior coworker. This can lead to feeling unqualified, that you’re compromising people’s time, and you may even worry you’re “annoying” your coworkers.
Requiring assistance is not exclusive to junior and mid-level engineers. For developers of all experience levels, asking for help is often the most important step in forward progress. After all, we work together for a reason: what we can accomplish together is greater than what we can do alone. Senior engineers work together to provide their specialized domain knowledge or skillsets, and it’s rare to find an engineer that can simply do everything (and do it well).
As critical as it is that we work together, it’s equally important that we as individuals are able to exercise a problem to its fullest extent. Research you perform individually will be the starting point for a collaborative effort, should it become necessary. Using a few tools and mental frameworks, we can ensure we are exercising a problem to its fullest extent. In many cases, these tools will prevent us from getting stuck in the first place.
Exploratory work
When first starting a task, ideally the context of the task is provided up front. Senior engineers responsible for writing a description of the task are equipped to guide you with the relevant information to complete it. If you see that the task is lacking the establishing context, this should prompt you to ask for the context to be included.
Hey Angie, I am starting to work on issue #123 and noticed there isn’t much context provided on where to begin my research. Do you have any documentation, references or samples in the code that I should be looking at?
Once you have the intial context, be sure you’re exercising the provided context first. It might be tempting to jump in and start writing new code immediately, but in my experience, this leads to unaware solutions that can cause more issues than they solve.
Consider the scope of the code in the provided context. What scope needs to be accounted for when solving the problem? In some cases, you are working on a highly specialized part of the code. Changes to it don’t have much of an impact to other code, if any at all. Other scenarios involve changing code that is highly impactful and broad. Common interfaces or functions used by many aspects of the code must be treated differently than single-purpose implementations.
Finally, do you have the requisite technical or domain knowledge to continue with the work? Tasks will range from purely technical to heavily domain-focused, and both present their own set of challenges. Combined with our understanding of scope, you’ll begin to have a clear set of expectations about what must happen to complete this task.
Broad technically-focused task
Exploration for this type of problem must involve research into a large set of use cases. Generally not given to junior engineers because of the complexity involved in creating a solution that’s correct, maintainable, and incorporates the ideal design.
Narrow technically-focused task
Only minimal use cases are required to understand the full context of the problem, and those use cases are focused on technical aspects of the code. May still require a high amount of exploration depending on the technical domain.
Broad domain-focused task
Must have previous knowledge of the domain or the available resources to learn extensive domain knowledge.
Narrow domain-focused task
May be able to use only the context provided by the problem to complete the task. There are usually contextual clues in the code to gain the requisite domain knowledge.
Something more
Tasks could heavily involve both domain and technical expertise. In some cases, it is crucial to consider if this task can be broken into smaller components to reduce the cognitive complexity in solving it. However, the most senior engineers may have the experience necessary to continue with solving a task of this nature, though it’s arguable that they shouldn’t (topic for another essay).
The expectations you gained from understanding the scope and knowledge required to complete the task set up the next actions you’ll take. A narrowly-focused technical task might mean you need to learn a specific topic using documentation, Stack Overflow, guides, or tutorials. A broadly-focused domain-heavy task may mean you need to read a book.
”…but that’s your job.”
A common debate among software engineers centers around the amount of context a task definition should provide. If we provide too little, most people will agree that even starting the task can be too challenging, let alone completing it. Advocates of a low amount of context might say something to the effect of, “why should we as a team spend all this time when it’s the job the individual that works the task?”
It’s up to your leaders and the team itself to determine how best to approach this. Consider the team composition. Newcomers to the team or company and junior engineers will need more context. Teams made up of seasoned experts may need just one sentence to be equally productive.
This sort of exploratory work is easily overlooked by newly minted software engineers, and it’s not the fault of the engineer. The work required by the team before a task is ready is often poorly committed to. Whether it’s a lack of experience from senior engineers who have never mentored, or business and time constraints preventing the exploratory work to be prioritized, it’s up to everyone ensure that the adequate provisions are made before writing any code.
Making progress
After the exploratory work is complete and you’re ready to implement a solution, it’s time to create and modify the code (bonus points for deleting code, but more on that in another post). Making progress on your solution can feel like a back and forth game moving between exploratory work and real progress. This is absolutely normal, and there are fewer scenarios where the preliminary exploratory work is enough to sustain the solution from conception to completion.
Starting over
As the old saying goes, it’s never too late to change paths, no matter how long you’ve been walking. When you continue making progress to the point that your progress shows you a better solution, you are allowed to Ctrl-z to your heart’s content and implement that solution.
Starting over doesn’t always need to mean a hard reset. You might be tempted to execute something like git reset head --hard. Before you throw away all your hard work, consider commiting on this branch and starting a new branch from the original head. When you make some progress on the new solution, chances are you will need to refer back to your first solution to make choices about implementation. Remember that the work you did up to this point is still contextual information that should be persisted.
What getting stuck looks like
With an assumption that we’ve made at least some progress, getting stuck in the middle of a task can look very different from scenario to scenario.
No solution yet
You haven’t found any solution yet, and you feel like any exploratory work you do to find one leads you down a path that’s too complicated or with too much unknown. This can be the most daunting and frustrating for new engineers, because without a possible solution, it’s easy to feel a sense of failure. What’s important is the context you’ve gained up to this point, since this will be the starting point for a shared effort with a colleauge.
One solution, but it doesn’t work
Based on your exploratory work, it should work. You’re not sure why though, and you can’t seem to find the missing component to the solution. This might be the “I copied it from Stack Overflow and it didn’t work” scenario which is one we have all encountered before. The main issue here is that you may not fully understand why the solution should work, and the tools coming up will help you arrive at a better understanding.
Multiple solutions, but not sure which is best
Often times there are several probable solutions that present themselves, and this can be overwhelming to new engineers. Similar to the complexity of coming up with a good variable name, having multiple solutions means you need to better understand the nature and impact of each solution. For new developers, this can feel out of reach because of a lack of experience on how to assess the differences and merits of one solution versus another.
Documenting knowns
Regardless of how we became stuck, we now have some set of knowns that have been uncovered from both the exploratory work and implementing the solution (up to this point). Before we accept being stuck, it’s important to document these and double-check their correctness. Any assumptions we make about the next steps are based on a set of knowns, so an error in correctness will need to be resolved before we can move forward.
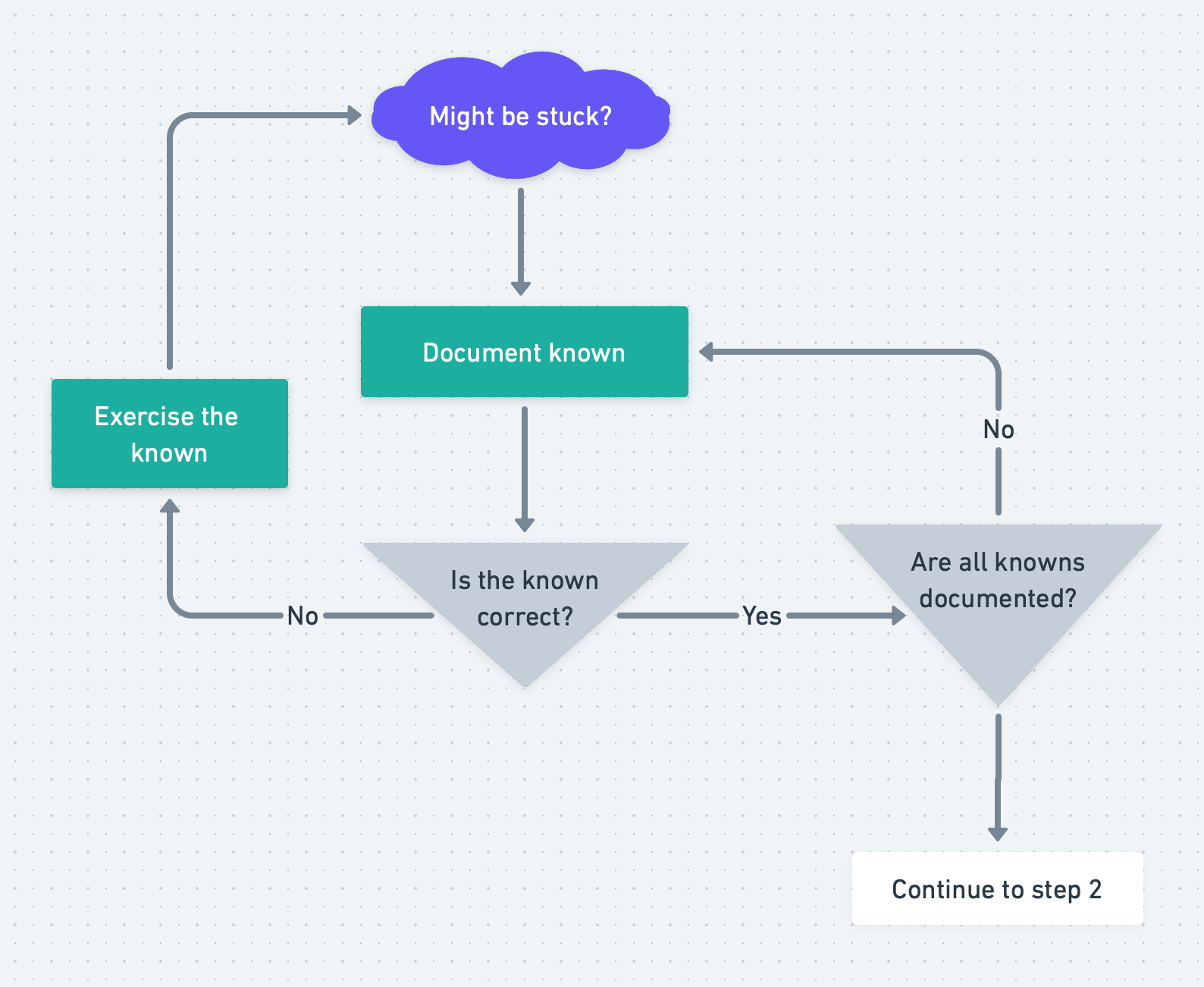
Ensure that you have documented all relvent information about the problem.
A known is any correct information that is relevant to the given scenario. The input that we receive as we start the task is often lacking context, and it’s our job to discover the context and use it to generate possible solutions to the problem. The more context that is known, the better our approach will be to defining the best solution.
Concrete example: Documenting Knowns
You’ve been given a task with only the description: “the search box stopped working”. At this point, there is no context we have that is beyond that offered by the description. We start researching by trying to use the search box. Through that experience we can document a handful of knowns:
- The user can type into the box.
- The user can see search results fill the type-ahead autocomplete as characters are entered.
- The search box visually is presented as expected.
We might be stuck even reproducing the bug, because the search results are showing up correctly. However, when clicking the button labeled “Search”, the screen goes blank. We reload the page, open developer tools, and try again. After observing details in the developer tools, we’re now able to add these knowns:
- The network request to the search endpoint returns an expected result (200 OK with a response body).
- There is an uncaught JavaScript error shown in the console about
cannot read property "map" of undefined.
After digging into the area of code specified by the error, we might be stuck. We need to then document any knowns about the code we’ve found through our research. This context will be important should we need to move beyond the Documenting Knowns step.
In my experience, documenting these knowns will generate new threads of context to research and explore. Presenting yourself a list of knowns offers your conscious mind a way to observe the context you’ve gained. When it’s all laid out in front of you, seeing gaps becomes much easier. And most importantly, with the knowns documented, you can provide immediate context to anyone you request help from (which they will appreciate immensely).
Finding unknowns
Becoming stuck is caused by some aspect of the problem blocked by a set of unknowns. Due to the nature of an unknown, it’s inherently harder to define than the knowns.
An unknown is any aspect of the problem of which we are not aware of the entire context. Context is gained by understanding what the unknown is, and outlining the steps to learn and understand the context. Below are a few examples of unknowns that I’ve encountered when solving a problem.
- An integration exists between our code and a third party. The context from the exploratory work allowed me to document one possible input from the third party, but I don’t know if there are other types of input.
- My code works in Chrome but not Firefox, and I’m not sure why.
- The library I’m using for making http requests isn’t throwing errors in the way I expected.
- The documentation for an API states one thing, but my observation in using the API does not match the expected result.
Breaking down the unknowns
The first technique to implement to un-stuck myself is to break it down into discrete components. Most often, unknowns stem from the interconnection of many different concepts or contexts. When you find that there are ways to separate the unknown into smaller pieces, start this process first.
Concrete example: Breaking Down the Unknowns
Here’s an example I encountered recently when I was able to avoid being stuck by breaking down the unknown. We had some logic in an API that was using a SQL COPY statement to ingest large amounts of data with low overhead. This statement was completely new to me—I believe I had read about it before, but never used it in practice.
Through the combination of exploratory work and actual progress, I found that the COPY statement was likely contributing to the issue I was trying to solve, but I didn’t know the inner workings of this statement in PostgreSQL. At this point, it’s a large unknown. I don’t even know what to try to address the problem due to the fact that I know nothing about it. So, I break it down into smaller pieces based on what I already know.
- The
COPYstatement skips some functionality related to the management of the table it is copying into. I don’t know what those management operations are. - In our case, the
COPYstatement is executed inside a transaction. I don’t know how this behaves in a transaction, and what the implications of this would be. - Our code was performing an
ANALYZEafter theCOPYwas complete. I don’t know what the implications of this are—is this a costly operation, or is it even necessary? Should it be performed in the transaction or as a separate operation? - Etc…
As you can see, breaking down what I initially thought was my lack of understanding of the COPY statement uncovered many interconnected contexts to the problem. With my new assessment, I can now exercise each of these items individually, rather than being overwhelmed by what seems like a significant unknown.
Unraveling the interconnected nature of a given unknown sometimes leads to something much bigger than what is expected of us as an individual. When breaking down the unknown, consider how much new work has been created for yourself. Does your team expect you to spend many days on exercising the context from these unknowns? It’s here where we can have a conversation with our leads and managers to determine if there’s an allowed alotment of time for this task. Many call this timeboxing, and it can be critical to ensuring we are not languishing in the team’s collective productivity.
Experimentation on unknowns
From the broken-down list, each item is a smaller context to exercise than the entirety of the unknown. Bit by bit, we can uncover new information and avoid being stuck. Additionally, to exercise each of these requires much smaller and simpler tests or experiments than trying to recreate the issue in its entirety.
The way that I recommend running these experiments is through contrived examples. One habit to get into is having a sort of “proving grounds” for these types of experiments ready to go. When you encounter an experiment you’d like to run, you can hop over to the proving ground to quickly run it in isolation from the rest of the complexity.
When you need a technical environment as a proving ground for your experiments, the best low-maintenance option is a dev environment such as repl.it or Code Sandbox. You can of course maintain these on your local machine, but for quick experimentation, nothing beats loading up a browser window and having ready-made sandbox.
Asking for help
Well, the time has come to ask for help. No worries! Because of the steps we took to determine we are truly stuck, we now have a contextual understanding of the problem that a colleague can use as a starting point. The first step is to collect our context into a neat little package. This is some sort of document that shows the results of your progress to this point. Below is an example of such a document you could write:
# Issue #123 Progress
## Progress
> Note here a list of commits/PRs you already made,
> possibly with any supporting information or documentation.
> For operational tasks, this could be actions you've
> already taken ("restarted process on server x").
## Knowns
> Place a list of your knowns here. We already ensured
> they are correct, so your colleague can use them
> as a starting point to understanding the problem.
## Unknowns
> Place a list of the unknowns here, including the
> background on any of them that you have already
> exercised. Your colleague is going to use these
> as the first place to answer questions they already
> have the solution for.
## Next steps
> Offer what you think are the next steps to finishing
> this task.Not only is the above document great for asking for help, but occasionally you need to pass a task to a colleauge for any other reason: you have an unexpected out-of-office, there’s a more urgent task that you’ve been asked to work on, etc. You can use the exact same procedure to stop a task part-way through the progress.
The document can then be used as a comment on an issue tracker (GitHub, Jira, etc) or as a message to the colleauge that will help you out. Your colleauges will thank you immensely for not only showing the work you’ve already put into trying to complete the task, but the time they have saved by not having to open up the entire task themselves.
Next steps
You and your colleague now have a shared understanding of the problem. You’re ready to collaborate to remove more of the unknowns, and it’s made easier by the exploratory work you did, combined with the documentation and context you shared with your coworker. Nicely done! From here, solving the problem together provides a resource for you to learn from a shared experience.
I hope this has provided a cohesive strategy for ensuring the productivity of both yourself and your team.